

























应用市场
极悦娱乐应用市场与生态伙伴通过产品级融合,为客户提供全面、专业、领先的产品及解决方案,共建产业互联。
前往应用市场 >

最近ChatGPT可谓是火遍了全球,它是由知名人工智能研究机构OpenAI于2022年11月30日发布的一个大型语言预训练模型(即Large Language Model,LLM)。ChatGPT可以理解人类的语言,并使用用户期望的风格和口吻进行回复。但它的能力远不止一个聊天机器人,它可以生成各种各样的文本,包括新闻报道、论文、PPT、代码、小说等。
LLM是什么呢?LLM指的是使用海量文本数据训练的语言模型,这种模型拥有强大的语言关联能力,能够从上下文中学习到更多信息。针对语言模型的研究很早就开始了,随着算力的不断发展,LLM的能力随着模型参数量的增加而显著提升。GPT全称Generative Pre-training Transformer,是由Google在2018年提出的一种预训练语言模型。它的核心是一个Transformer decoder。
论文:《Improving Language Understanding by Generative Pre-Training》
在GPT-1诞生之前,传统NLP模型仍然使用大量数据对模型进行有监督学习。这种有监督学习任务存在明显缺点:
1、需要大量人工标注数据,耗时且昂贵。
2、泛化性和可迁移性差。
这篇论文提出一种两阶段的半监督训练方法,具体是通过大规模未标注数据预训练一个无监督语言模型,下游再根据不同任务进行有监督微调。
无监督预训练是半监督学习的一个特例,目的不是修改监督学习的目标,而是找到一个好的优化初始点。预训练是一种正则化方案,在深度神经网络中的泛化性更强。
给定一个无标注样本库的token序列集合 ,语言模型的目标就是最大化下面的似然值。也就是通过前面的tokens,预测下一个token。
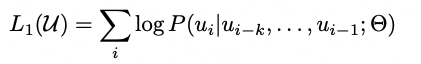
其中,k是滑动窗口的大小,P是条件概率。模型参数使用SGD进行优化。
GPT-1使用了12层Transformer decoder结构。

其中,U表示token的文本向量, 表示token embedding矩阵, 表示位置向量矩阵。每个token会通过transformer block被编码,最后再经过一个线性层+softmax,得到下一个token的预测分布。结构还是非常简单的。
得到无监督的预训练模型后,将得到的参数值直接应用于有监督任务中。对于一个有标签的数据集C,每个实例有m个输入tokens: 。将这些tokens输入到预训练模型中,得到transformer block的输出向量 ,再经过一个全连接+softmax,得到预测结果y:
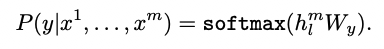
有监督学习的目标即最大化上述概率:
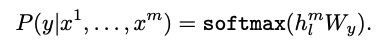
值得一提的是,作者发现,把预训练目标作为辅助目标加入下游任务loss中,将会提高有监督模型的泛化性能,并加速收敛。因此,有监督任务的最终优化目标是:
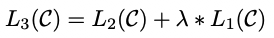
对于文本分类任务而言,可以直接对预训练模型进行fine-tune。由于我们的预训练模型是在连续的文本序列上训练的,对于某些具有结构化输入(比如有序的句子对,或是文档、问题、答案的三元组等)的task,需要我们对输入进行一些修改。文章中,将结构化输入转换成预训练模型可以处理的有序序列。

BooksCorpus dataset(包含7000多本未发表的书籍)
文章主要是通过下游有监督任务的效果对策略进行验证。在12个数据集上,GPT-1在其中9个数据集上的表现都超过了state-of-the-art的模型。以分类为主的数据集为例,如下所示。(此时BERT还没有诞生。)

论文:《Language Models are Unsupervised Multitask Learners》
在GPT-1发表的4个月后,BERT出现,赚足了眼球。据闻BERT的作者花了1~2个月的时间做出了这个模型,可能正是受到了GPT-1的启发。我们知道,GPT-1使用的是transformer decoder,而BERT使用的是transformer encoder,当时BERT在公开数据集上的效果也是明显优于GPT。GPT-1的作者在BERT发表的4个月后,又发表了GPT-2。GPT-2尝试在GPT-1的基础上增加模型大小和参数规模,但在预训练+微调的训练框架下,仍然打不过同样参数大小的BERT;作者想到另一个切入点,以zero-shot作为这篇文章的创新点,也是比较新颖。
核心思想即,训练一个通用的预训练模型,使下游任务无需手动生成或标记训练数据集,更无需更改预训练模型的参数或结构。
由于语言文本具有自然时序性,因此通常可将联合概率因式分解为条件概率的乘积:

简单理解就是,在已知输入的条件下,预估输出的条件概率分布:p(output | input)。对于下游不同task的有监督任务来说,它可以建模成:p(output | input, task)。比如:
这其实就是Prompting方法。作者认为,监督目标与无监督目标相同,因此无监督目标的全局最小值也是有监督目标的全局最小值。换言之,任意监督任务均是无监督语言模型的子集,只要语言模型的容量足够大,训练集足够丰富,仅仅依赖语言模型的学习,便可以同时完成其他有监督任务的学习。作者称之为“无监督多目标学习”。
训练数据:为了实现多任务无监督的zero-shot,我们希望数据集越大越丰富越多样越好。作者调研了如下几个数据集:
1、类似于Common Crawl的网页爬虫,多样性好且文本趋近无限,虽然比当前语言模型的数据集大很多数量级,但存在严重的数据质量问题。
2、自建了一个强调文档质量的WebText数据集。具体的,媒体平台Reddit爬到了所有被用户分享出站的链接,并限制每个链接的内容至少获得三个Karma(类似点赞收藏等正反馈)。作者认为,被用户分享的链接,往往是人们感兴趣的、有用的或者有趣的内容。
3、生成的WebText数据集是上述4500万链接的文本子集。对其进行后处理:1)剔除2017年12月之前创建的链接;2)去重;3)启发式清理;4)移除了所有维基百科文档,考虑到它是其他数据集的通用数据源,避免与下游的测试评估数据重叠。最终生成800万个文档,40GB的文本。
模型这部分跟GPT-1相比区别不大,在GPT-1的基础上做了几个改进。
文章尝试了四种模型,其中117M对应GPT-1(以及Bert-base),345M对应Bert,最大的模型(即GPT-2)为1542M(15亿参数)。

仅通过zero-shot学习,GPT-2在8个语言模型任务中,有7个超过了state of the art的方法。
在不同数据集上的表现如下:
1、Children’s Book Test 命名实体识别任务:

2、LAMBADA是用来测试模型捕捉长期依赖能力的数据集,任务是预测句子中的最后一个词(人类至少需要50个上下文token才能预测准确)。GPT-2将ACC从19%提升到了52.66%,加入stop-word标记后,ACC提升到63.24%。
3、Winograd Schema Challenge,GPT-2的准确度比state of the art方法提高了7%。

4、在阅读理解任务中,GPT-2超过了四个base模型中的3个。
5、GPT-2在摘要总结任务上的能力不理想,仅接近经典神经系统的表现。
6、翻译任务:在法译英的任务上,GPT-2虽然比当前最好的无监督机器翻译方法差很多,但却优于另外几个无监督机器翻译基线模型。

GPT-2的最大贡献就是验证了通过海量数据和大量参数训练出来的语言模型,可以迁移到下游其他任务,无需额外训练和fine-tune。通过Prompting方法调动了zero-shot学习的能力。但大量实验表明,GPT-2的无监督学习能力还有很大的提升空间,GPT-2在很多不同的task中,有些表现良好,但在某些领域仍然表现欠佳,比如summarization、QA等。作者提出,模型容量仍然是无监督模型在问答领域表现不佳的主要原因。随着模型参数量的增加,GPT-2的效果也会稳步提升,这就有了未来GPT-3的大力出奇迹。
极悦娱乐产品更多介绍:www.heyyen.com












 豫公网安备 41010702002713号
豫公网安备 41010702002713号




