

























应用市场
极悦娱乐应用市场与生态伙伴通过产品级融合,为客户提供全面、专业、领先的产品及解决方案,共建产业互联。
前往应用市场 >

基于生成式人工智能的模型和应用程序正被各行各业迅速采用,以增强人类在广泛任务中的应用。OpenAI的ChatGPT的发布就像是打开了潘多拉魔盒,大型语言模型(Large Language Model,LLM),例如GPT3.5和GPT4。这些模型在各种任务上都表现出色,比如:文学风格小说创作,GitHub Copilot代码生成、AI医疗知识问答、Michelle HuangAI情感治疗等等,但是它们的训练和推理开销很高,需要大量的计算资源。机器学习(ML)社区目前在谈论一个新术语:“LLMOps”。Meta团队提出了一个名为LLMOps(Large Language Model Operations)的概念。LLMOps旨在分解和量化LLM的计算成本,为研究人员和开发者提供更好的洞察力,以优化和加速模型训练和推理。
LLMOps框架将LLM的计算成本分为四个部分:计算图构建、正向传播、反向传播和参数更新。对于每个部分,LLMOps都提供了一种独特的方法来量化计算成本。
目前业界术语 LLMOps 代表大型语言模型操作。LLMOps简短定义是是LLM的MLOps。这意味着LLMOps是一组工具和最佳实践,用于管理LLM驱动的应用程序的生命周期,包括开发,部署和维护。
LLMOps 是 LLM 的 MLOps方式
首先,让我们根据语义分析,术语 LLM 和 MLOps:
因此,LLMOps 是一组工具和最佳实践,用于管理 LLM 驱动的应用程序的生命周期。它可以被视为MLOps的一个子类别,因为LLM也是ML模型。
降本增效、费用预测和控制、模型监控和管理、自动化扩缩容
如今,大家都知道AIGC时代或LLM 超大模型训练模型需要大量的计算资源和存储资源,因此训练成本较高。以下是一些降低 LLM 超大模型训练成本的基本理论方法:
很明显,构建生产就绪的LLM驱动的应用程序有其自身的一系列挑战,这与使用经典ML模型构建AI产品不同。为了应对这些挑战,我们需要开发新的工具和最佳实践来管理LLM应用程序生命周期。因此,我们看到“LLMOps”一词的使用有所增加。
LLMOps 中涉及的步骤类似于 MLOps。但是,由于基础模型的出现,构建LLM驱动的应用程序的步骤有所不同。与其从头开始训练LLM,重点是使预先训练的LLM适应下游任务。
早在一年多前,Andrej Karpathy 就描述了我们将如何构建人工智能产品在未来发生变化:
但最重要的趋势是,由于微调,从头开始训练神经网络的整个设置[...]由于微调而迅速过时,特别是随着GPT等基础模型的出现。这些基础模型仅由少数具有大量计算资源的机构进行训练,大多数应用程序都是通过对网络的一部分进行轻量级微调、快速工程或将数据或模型提炼成更小的专用推理网络的可选步骤来实现的....— 安德烈·卡尔帕西
这句话在第一次阅读时可能会让人不知所措。但它准确地总结了正在发生的一切,所以让我们在下面的小节中逐步解压缩它。
基础模型是在大量数据上预先训练的LLM,可用于广泛的下游任务。由于从头开始训练基础模型既复杂又耗时且极其昂贵,因此只有少数机构拥有所需的训练资源。
举个例子:根据 Lambda Labs 在 2020 年的一项研究,使用 Tesla V3 云实例训练 OpenAI 的 GPT-175(具有 355 亿个参数)将需要 4 年和 6 万美元。
AI的Linux时刻:我们希望这些不可思议的AI工具符合每个人的最大利益,而不仅仅是受少数大玩家的影响。要做到这一点,我们需要保持难以置信的善意,成为一个开源社区,在那里我们可以在彼此进步的基础上再接再厉,抵制有害的越界行为。这将是一个巨大的挑战,但机会是值得的!就像Linux时代一样,我们的挑战是弄清楚如何将开源原则体现为个人和组织,为人工智能时刻重新构想。就像Linux社区为几十年的计算奠定了基础一样,我们可能有机会与人工智能一起建立下一代计算的基础。
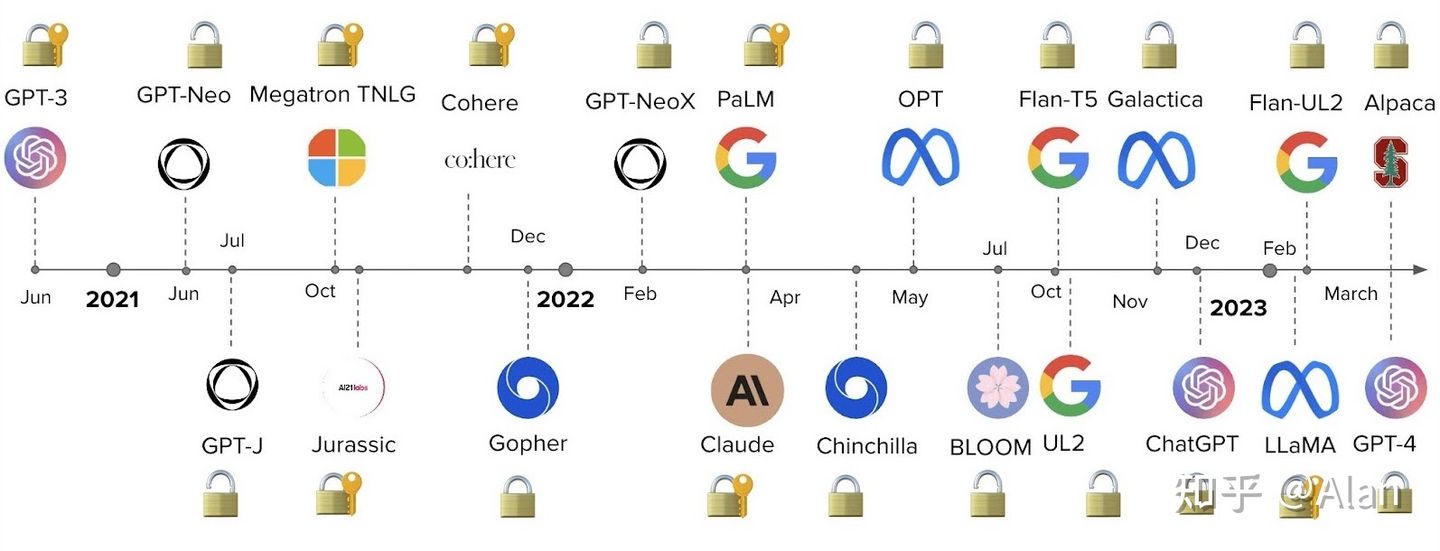
人工智能目前正在经历“Linux时刻”(AI的Linux时刻:开源AI模型情书,大家一起书写)。目前,开发人员必须根据性能、成本、易用性和灵活性之间的权衡,在两种类型的基础模型之间进行选择:专有模型或开源模型。

专有模型是拥有大型专家团队和大量 AI 预算的公司拥有的闭源基础模型。它们通常比开源模型大,因此具有更好的性能。它们也是现成的,因此易于使用。
专有模型的主要缺点是其昂贵的API(应用程序编程接口)。此外,闭源基础模型为开发人员提供的适应灵活性较低或根本没有。
专有模型提供程序的示例包括:
开源模型通常作为目前最大社区中心在Hugging Face上组织和托管。通常,它们是较小的模型,其功能低于专有模型。但从好的方面来说,它们比专有模型更具成本效益,并为开发人员提供了更大的灵活性。
开源模型的示例包括:
选择基础模型后,您可以通过其API访问LLM。如果您习惯于使用其他API,那么使用LLM API最初会感到有点奇怪,因为事先并不总是清楚什么输入会导致什么输出。给定任何文本提示,API 将返回文本完成,尝试匹配您的模式。
下面是如何使用 OpenAI API 的示例。您将 API 输入作为提示:
例如 .prompt = "Correct this to standard English:\n\nShe no went to the market."
import openai openai.api_key = ... response = openai.Completion.create( engine = "text-davinci-003", prompt = "Correct this to standard English:\n\nShe no went to the market.", ... )API 将输出包含完成response
response['choices'][0]['text'] = "She did not go to the market."
主要的挑战是LLM尽管很强大,但并不是全能的,
因此,关键问题是:你如何让LLM给出你想要的输出?
LLM生产调查中提到的一个受访者关注的是模型的准确性和幻觉。这意味着以您想要的格式从LLM API获取输出可能需要一些迭代,而且,如果LLM没有所需的特定知识,他们可能会产生幻觉。为了解决这些问题,您可以通过以下方式使基础模型适应下游任务:


在经典 MLOps 中,ML 模型在保留验证集 [5] 上进行验证,并使用指示模型性能的指标。但是您如何评估LLM的性能?您如何确定响应是好是坏?目前,组织似乎正在A / B测试他们的模型[5]。
为了帮助评估LLM,出现了像HoneyHive或HumanLoop这样的工具。
LLM的完成可以在版本之间发生巨大变化[2]。例如,OpenAI已经更新了其模型,以减少不适当的内容生成,例如减少仇恨、政治、宗教等言论。模型可能会生成可能不安全的内容,无论是提示还是非提示。不准确可能会产生严重后果,特别是对于可能导致潜在伤害的关键用例,例如不正确或误导性的医疗信息和鼓励自残、甚至是邪教思想。因此,“作为AI语言模型”本质上它只是一个知识量丰富的学者,它无法衡量给出答案价值是否会影响到每个人的人生观、世界观,避免给出错误的答案,因此,部署与监控每次AI问询,对于给出的答案做正确的价值判断!


这表明构建 LLM 驱动的应用程序需要监视底层 API 模型中的变化。
已经出现了用于监控LLM的工具,例如Whylabs或HumanLoop。
下面会给出业界目前在这个LLMOps方向系统架构图:(仅供参考)


生成性人工智能的加速采用才会发生。生成性人工智能Ops或LLMOps工作流程需要在训练、调整、部署、监控和解释方面取得进展,以便解决微调、部署和推理挑战。这些变化将很快到来——例如,谷歌人工智能最近推出了缪斯36,它使用掩蔽生成变压器模型而不是像素空间扩散或回归模型来创建视觉效果,与Imagen相比,在更小的9亿参数占用范围内,运行时间加快了10倍。
MLOps 和 LLMOps 之间的差异是由于我们使用经典 ML 模型与 LLM 构建 AI 产品的方式不同造成的。这些差异主要影响数据管理、试验、评估、成本和延迟。
在经典 MLOps 中,我们习惯于数据饥渴的 ML 模型。从头开始训练神经网络需要大量标记数据,甚至微调预训练模型也至少需要几百个样本。尽管数据清理是 ML 开发过程中不可或缺的一部分,但我们知道并接受大型数据集存在缺陷。
在LLMOps中,微调类似于MLOps。但快速工程是一种零镜头或少镜头的学习设置。这意味着我们只有很少的样本,但手工挑选[5]。
在 MLOps 中,无论是从头开始训练模型还是微调预先训练的模型,试验看起来都类似。在这两种情况下,您都将跟踪输入(例如模型体系结构、超参数和数据增强)和输出(例如指标)。
但在LLMOps中,问题是是提示工程师还是微调[2,5]。尽管 LLMOps 中的微调与 MLOps 相似,但提示工程需要不同的试验设置,包括提示管理。
在经典 MLOps 中,使用评估指标在维持验证集 [5] 上评估模型的性能。由于LLM的性能更难评估,目前组织似乎正在使用A / B测试[5]。
传统MLOps的成本通常在于数据收集和模型训练,而LLMOps的成本在于推理[2]。虽然我们可以预期在实验期间使用昂贵的API会产生一些成本[5],但C.Huyen[2]表明长提示的成本是推理中的。
LLM生产调查中提到的另一个关注的问题是延迟。LLM 的完成长度会显著影响延迟 [2]。尽管在 MLOps 中也必须考虑延迟问题,但它们在 LLMOps 中更为突出,因为这对于开发期间的实验速度 [5] 和生产中的用户体验来说是一个大问题。
LLMOps 是应对未来超大规模机器学习技术应用于Ops运维管理中的一种方法,它可以帮助企业更直观通过人类自然语言方式实现机器学习模型的自动化部署和管理,提高效率和可靠性。它应用价值在于:
LLM驱动的应用程序投入生产会带来一系列挑战,这导致了一个新术语“LLMOps”的出现。它指的是用于管理LLM驱动的应用程序生命周期的一组工具和最佳实践,包括开发、部署和维护。
未来,随着人工智能技术的不断发展,LLMOps 将会得到更广泛的应用。企业将会更加重视超大模型的机器学习模型的管理和维护,同时也会更加关注数据隐私和安全问题、AI的道德和伦理问题。因此,LLMOps 将会不断地发展和完善,为企业提供更加高效、可信任、高安全的大规模模型的机器学习服务。
极悦娱乐产品更多介绍:www.heyyen.com












 豫公网安备 41010702002713号
豫公网安备 41010702002713号




